scikit-learn
About scikit-learn
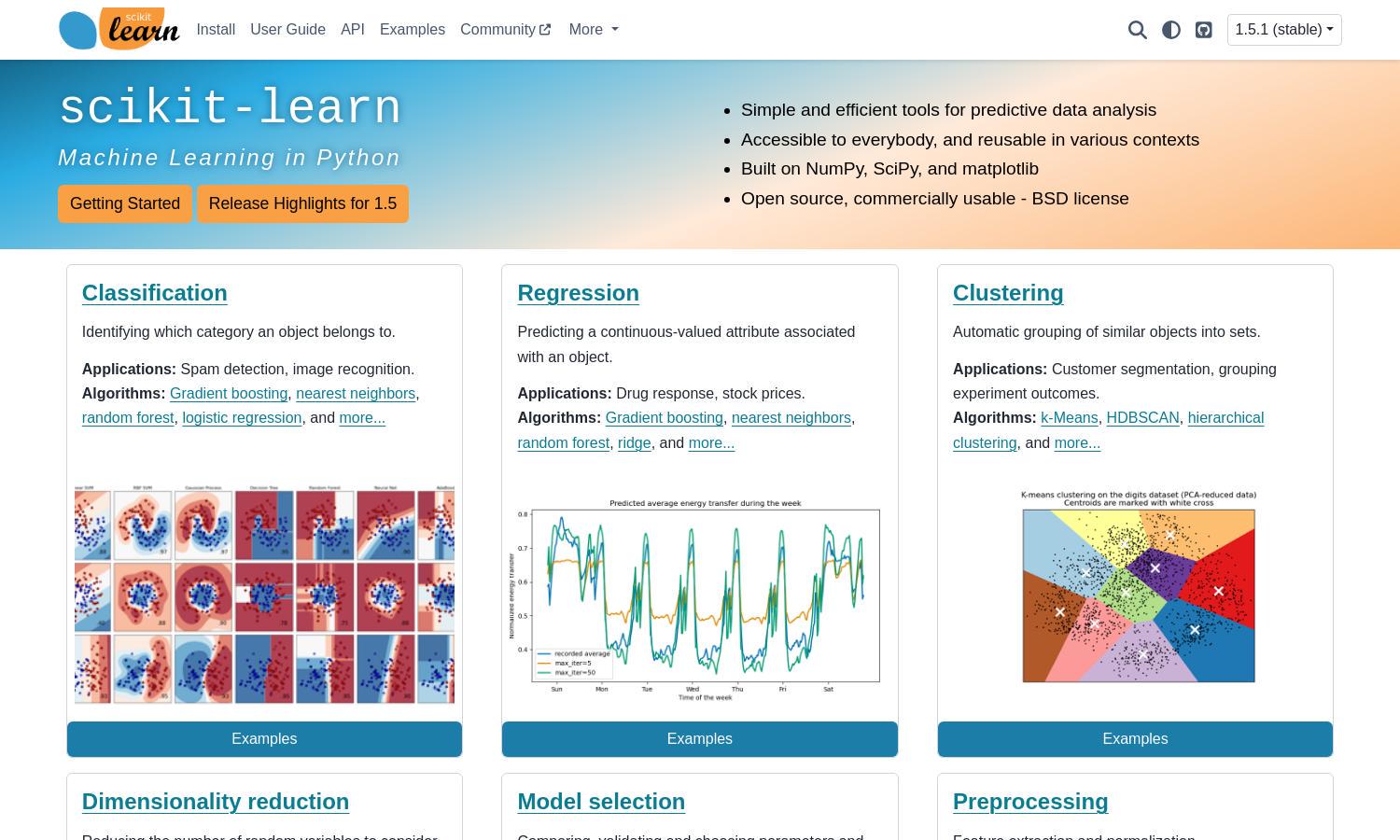
scikit-learn is an open-source Python library designed for machine learning and data analysis. It targets developers, data scientists, and researchers by providing efficient algorithms for tasks like classification and regression. Its unique feature lies in its ease of use, enabling effective predictive modeling without extensive coding.
scikit-learn is free to use as an open-source platform. There are no subscription tiers as it offers comprehensive features at no cost. Contributions and support are welcomed from the community, ensuring continuous development. Users benefit from access to state-of-the-art ML tools without financial investment.
The user interface of scikit-learn is designed to facilitate seamless navigation and efficient interaction. With well-organized documentation, users can easily find tutorials and examples, enhancing their learning experience. The layout emphasizes clarity, enabling users to focus on implementing machine learning techniques effectively.
How scikit-learn works
Users interact with scikit-learn by installing the library in their Python environment. They begin by importing the necessary modules, followed by data preprocessing and model selection. Users can then apply various algorithms for classification, regression, or clustering based on their data needs, benefiting from simple, reusable code structures.
Key Features for scikit-learn
Simple and Efficient Tools
scikit-learn's core feature is its simple and efficient tools for predictive data analysis. This library streamlines the machine learning process, enabling users to implement complex algorithms easily and effectively, making data-driven insights more accessible for everyone.
Wide Range of Algorithms
scikit-learn offers a comprehensive array of algorithms for various tasks, including classification, regression, and clustering. This diverse selection allows users to tailor their analysis to specific needs, enhancing their ability to derive meaningful insights from data and optimize their machine learning projects.
Open Source and Community Driven
As an open-source project, scikit-learn thrives on community contributions. This collaborative approach ensures that the library continues to evolve and improve, providing users with innovative features and timely updates that enhance the machine learning experience and keep the library at the cutting edge.
You may also like: