ImageBind by Meta AI
About ImageBind by Meta AI
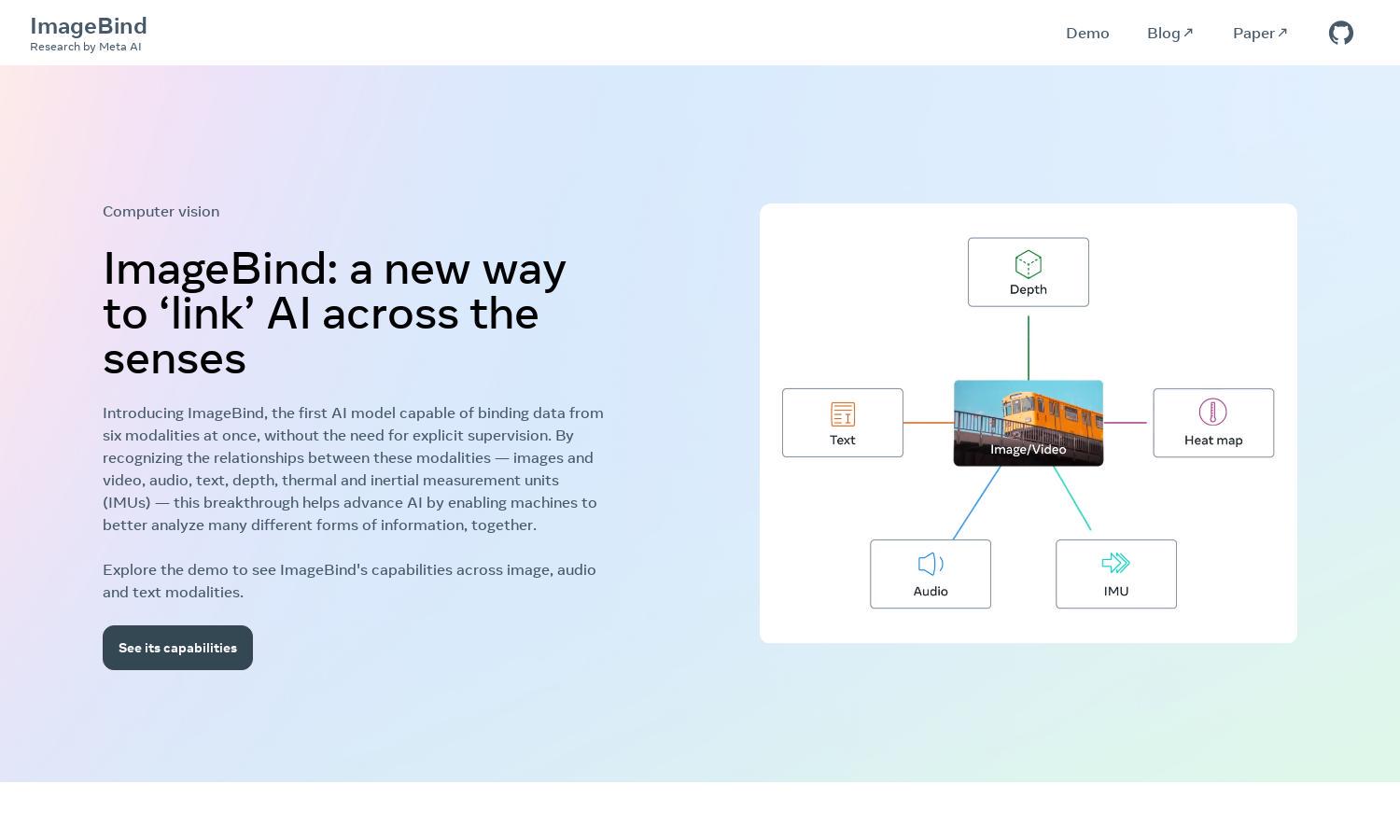
ImageBind is a groundbreaking multimodal AI platform by Meta AI that integrates six types of sensory inputs. Targeting researchers and developers, it innovates AI's capability to analyze and generate cross-modal data seamlessly. With no need for explicit supervision, it effectively addresses complex data relationships, enhancing AI applications.
ImageBind offers an open-source model, allowing free access to its innovative features. Users can explore its capabilities at no cost, while potential future subscription tiers may offer enhanced functionalities and support. Upgrading could provide access to exclusive tools and advanced features tailored for professional use.
ImageBind’s user interface is designed for simplicity and efficiency, providing an intuitive layout for easy navigation. Users can seamlessly access diverse multimodal features through organized menus, enhancing their experience. Unique elements like integrated demo tools ensure users can experiment conveniently, making ImageBind accessible to all users.
How ImageBind by Meta AI works
Users start with ImageBind by exploring its demo, where they can upload images, audio, or text inputs. The platform then processes these sensory inputs using its advanced multimodal model, binding the data without explicit supervision. Users can seamlessly navigate through results, leveraging its capabilities for tasks like cross-modal search or generation.
Key Features for ImageBind by Meta AI
Multimodal Binding Capability
ImageBind's core functionality is its unique capability to bind various sensory modalities into a singular embedding space. This innovative feature enhances data analysis and allows users to explore relationships across images, audio, and text, improving overall AI performance and usability.
Zero-shot Recognition Performance
ImageBind excels in zero-shot and few-shot recognition across modalities, achieving state-of-the-art results without requiring specialized training for each type of input. This feature makes it significantly advantageous for users needing efficient recognition without extensive data preparation.
Cross-Modal Generation
ImageBind supports cross-modal generation, allowing users to create content using multiple sensory modalities. This feature enables innovative applications like audio-to-image generation or multimodal content creation, broadening the scope of creative possibilities and enhancing user interaction.