LLM Reference
LLM Reference helps tech leaders quickly find and compare the best AI models and providers for their specific project needs.
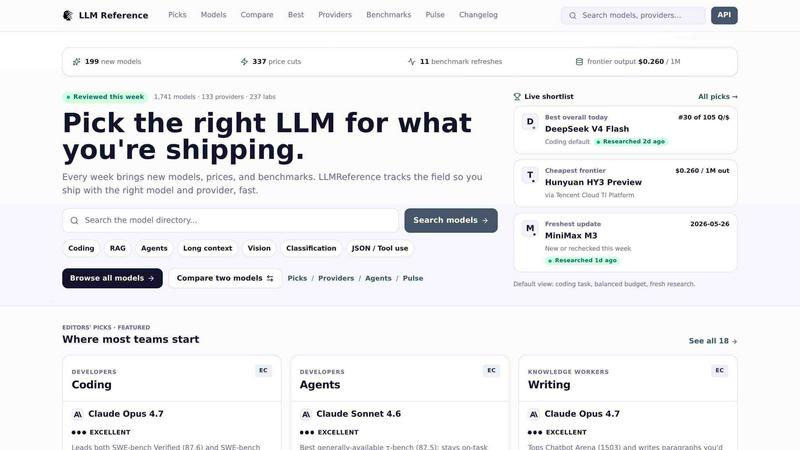
About LLM Reference
LLM Reference is a decision-support directory built for engineers and technology leaders who need to choose the right large language model (LLM) and provider in today's fast-moving AI landscape. It tracks over 1,700 models from more than 130 providers and 235 research labs, with data refreshed weekly to include new releases, verified price changes, and benchmark updates. The core value proposition is simple: stop wasting time hunting through scattered sources and start shipping with confidence. Whether you are building a coding assistant, an agentic workflow, a writing tool, or a research pipeline, LLM Reference gives you a single, trustworthy place to compare models side-by-side, see who offers the cheapest pricing for frontier output, and browse curated editors' picks for specific tasks like coding, agents, writing, research, image generation, and video creation. The site is designed for fast triage — you can quickly identify the right model for your job, determine the most cost-effective provider, and get back to building. With a Pulse feed that highlights what changed this week, including new models, price cuts, and benchmark refreshes, LLM Reference keeps you informed without the noise. It is built by the Data Advantage project and updated daily, making it an essential resource for anyone who needs to stay current with the exploding LLM ecosystem.
Features of LLM Reference
Comprehensive Model Directory
Browse a searchable directory of 1,744 models from 133 providers and 235 labs. You can filter by task type such as coding, RAG, agents, long context, vision, classification, and JSON or tool use. Each model entry includes key details like benchmark scores, pricing per million output tokens, and provider availability. This feature ensures you never miss a relevant model, whether it is a frontier release from a major lab or a specialized open-weight alternative from a smaller provider.
Side-by-Side Model Comparison
Compare any two models directly to see how they stack up on performance, pricing, and benchmarks. This feature eliminates the guesswork of evaluating models from different providers with different pricing structures. You can quickly assess which model offers the best value for your specific use case, such as comparing Claude Opus 4.7 against GPT-5.5 for writing quality or DeepSeek V4 Pro against GLM-5.1 for coding tasks. The comparison view is clean and actionable, letting you make an informed decision in seconds.
Editors' Picks and Curated Boards
LLM Reference features expert-curated picks for every major use case, organized by audience. Developers get boards for coding, agents, tool use, open weights, long context, and cheap models. Knowledge workers find writing, research, summarization, docs Q&A, translation, and data or SQL boards. Creatives see image, video, voice TTS, transcription, music, and image editing boards. Each pick includes a quality rating and links to eligible alternatives, so you always have a starting point that has been vetted by the team.
Pulse Feed and Weekly Updates
The Pulse feed is your weekly snapshot of what changed in the LLM market. It tracks new models (43 added this week), verified price cuts (39 this week), and benchmark refreshes (58 this week with 782 scores tracked). It also highlights frontier output pricing, currently at $0.260 per million tokens for the cheapest frontier model. This feature saves you from manually monitoring dozens of sources and ensures you never miss a critical update that could affect your deployment decisions.
Use Cases of LLM Reference
Choosing a Model for a Coding Project
When you are building a software tool or automating code generation, you need a model that excels at programming tasks. LLM Reference helps you quickly identify the best coding models by comparing SWE-bench Verified and SWE-bench Pro scores. For example, Claude Opus 4.7 leads both benchmarks with scores of 87.6 and 64.3 respectively, making it the surest hand for real pull requests. You can also filter by open weights if you need to self-host, or by cheap models if you are on a tight budget.
Selecting a Provider for Agentic Workflows
Agentic applications require models that can handle long tool loops, self-correct without prompting, and maintain context across many steps. LLM Reference highlights Claude Sonnet 4.6 as the best generally available agent model with a tau-bench score of 87.5. You can compare it against alternatives like GLM-5 or GPT-5.4, and then check which provider offers the lowest pricing for that specific model. This ensures your agents stay performant without blowing your inference budget.
Picking a Model for Creative Content Generation
Whether you are generating images, videos, or music, LLM Reference has a curated board for each creative task. For photorealistic image generation, FLUX.2 Dev is the current leader with excellent text rendering and brand consistency. For video, Veo 3.1 offers the best overall quality with 30-second clips, native audio, and up to 4K resolution through Vertex AI. You can compare these against alternatives like DALL-E 3, Midjourney v6+, Runway Gen-4.5, or Wan 2.7 to find the perfect fit for your creative project.
Benchmarking Research and Writing Quality
For knowledge workers who need to synthesize information or produce high-quality written content, LLM Reference provides detailed benchmark data. Claude Opus 4.7 tops the GPQA Diamond benchmark at 94.2 and writes paragraphs you would ship, with strong tone understanding and editing capabilities. You can compare it against GPT-5.5 or Gemini 3 Pro for research tasks, and check the Chatbot Arena score (1503 for Claude Opus 4.7) to validate real-world user preference. This helps you choose a model that produces accurate, footnoted, and publishable work.
Frequently Asked Questions
How often is LLM Reference updated?
LLM Reference is refreshed weekly with new model releases, verified price changes, and benchmark updates. The Pulse feed provides a summary of what changed each week, including the number of new models, price cuts, and benchmark refreshes. The site is updated daily by the Data Advantage project, so you can always find the most current information.
Can I compare models from different providers?
Yes, the side-by-side model comparison feature allows you to compare any two models from different providers. You can see benchmark scores, pricing per million output tokens, and other key metrics in a single view. This makes it easy to evaluate, for example, whether a model from DeepSeek offers better value than one from Google or Anthropic for your specific task.
What are Editors' Picks and how are they selected?
Editors' Picks are curated recommendations for specific use cases like coding, agents, writing, research, image, and video. They are selected based on a combination of benchmark performance, real-world user feedback (such as Chatbot Arena scores), and pricing. Each pick is rated as Excellent, Good, or Fair, and is accompanied by a list of eligible alternatives. The picks are updated regularly to reflect new releases and changing market conditions.
How do I find the cheapest provider for a model?
LLM Reference tracks pricing for every model and provider in its directory. You can use the model search or comparison feature to see the cost per million output tokens for each provider. The Pulse feed also highlights the cheapest frontier model each week, currently Hunyuan HY3 Preview via Tencent Cloud TI Platform at $0.260 per million output tokens. This helps you minimize inference costs without sacrificing performance.
Pricing of LLM Reference
LLM Reference is currently available as a free resource. There are no paid plans or subscription tiers mentioned on the website. The site is a project by Data Advantage, LLC and is accessible to all users without any cost. You can browse models, compare them, view editors' picks, and check the Pulse feed without any restrictions. If pricing plans are introduced in the future, they will likely be announced on the site.
Similar to LLM Reference
CartLens
CartLens scans your receipts to show if you overpaid and where to find better prices nearby, keeping your spending data private and secure.
ImageToSTL.online
ImageToSTL.online turns your PNG or JPG into a watertight 3D print file instantly and privately in your browser for free.
EchoLeads AI
EchoLeads AI uses intelligent voice agents to automate cold calling, lead qualification, and appointment scheduling so your sales team can focus on.
BlueHumanizer
BlueHumanizer turns stiff AI text into clear, natural writing with one click, keeping your meaning and tone intact.
imagetostl
Turn any image into a 3D printable STL model in seconds with fast, easy generation and a free preview.