Agenta vs OpenMark AI
Side-by-side comparison to help you choose the right AI tool.

Agenta streamlines LLM app development with collaboration, prompt management, and clear evaluation to boost reliability.
Last updated: March 1, 2026
OpenMark AI lets you benchmark over 100 AI models for cost, speed, quality, and stability tailored to your specific tasks in minutes.
Last updated: March 26, 2026
Visual Comparison
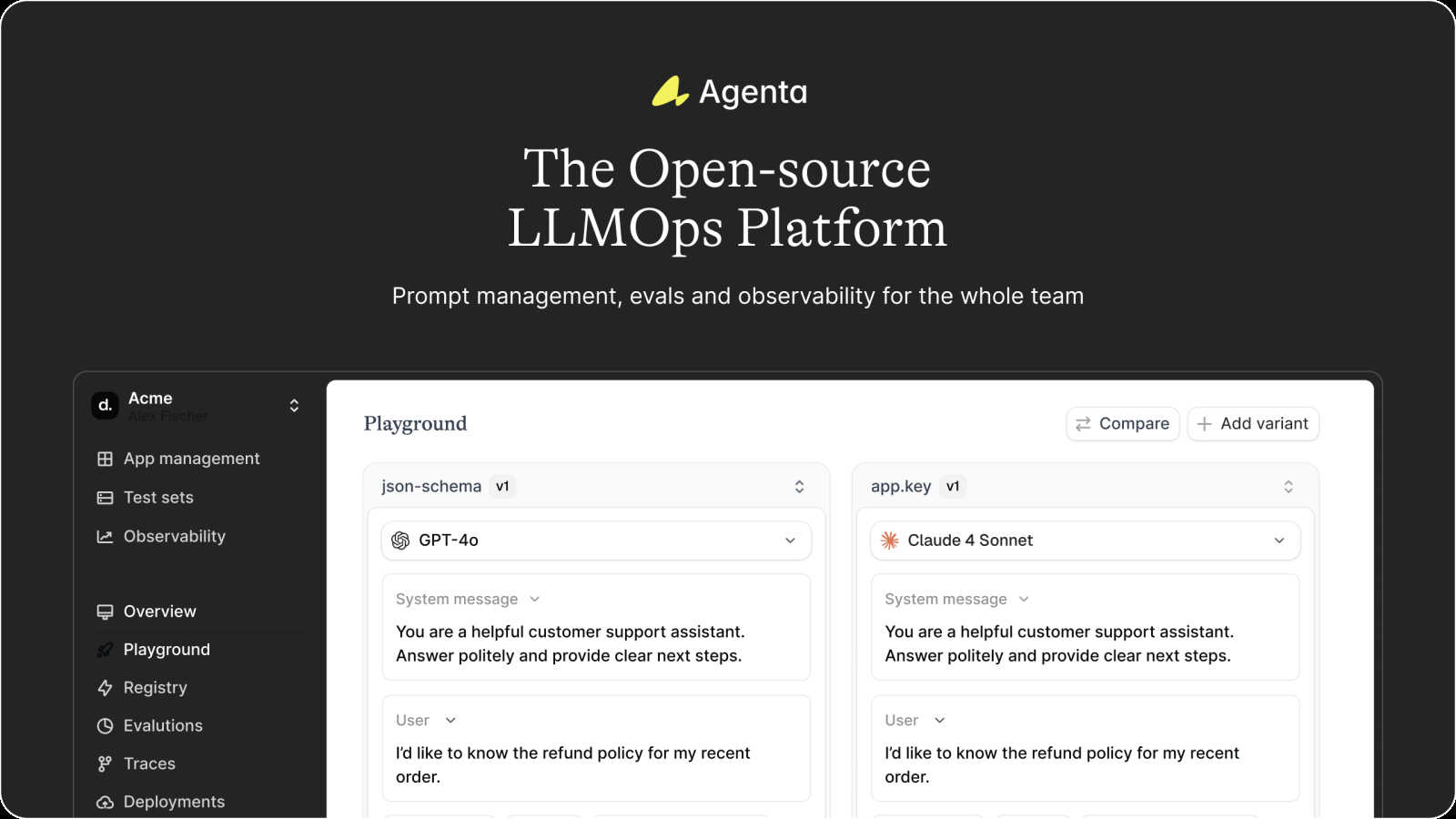
Agenta
OpenMark AI

Feature Comparison
Agenta
Centralized Prompt Management
Agenta offers a unified platform to centralize all prompts, evaluations, and traces in one location. This eliminates the chaos of scattered documents and communications, providing a single source of truth for the entire team.
Collaborative Evaluation Environment
With Agenta, teams can create and monitor evaluations collaboratively. This feature enables users to run systematic and automated evaluations, providing a structured process to validate performance and gather insights effectively.
Integrated Observability Tools
Agenta features robust observability tools that allow teams to trace every request and pinpoint failure points with precision. This enhances the debugging process, making it easier to identify and resolve issues in production quickly.
Human-Centric Experimentation
Agenta empowers domain experts to safely edit and experiment with prompts without needing to dive into code. This collaborative approach allows product managers and subject matter experts to contribute actively to the evaluation and improvement of AI applications.
OpenMark AI
Intuitive Task Description
OpenMark AI allows users to describe their benchmarking tasks using simple language. This user-friendly approach eliminates the need for technical jargon, making it accessible for teams of all skill levels. You can easily set up your desired tests without extensive prior knowledge.
Real-Time Model Comparison
The platform facilitates real-time comparisons of over 100 models, allowing you to run benchmarks across various tasks simultaneously. This feature provides immediate insights into which model performs best for your specific requirements, ensuring that you select the most suitable option for your needs.
Cost Efficiency Tracking
OpenMark AI emphasizes understanding the real costs associated with API calls. It provides detailed insights into the cost per request, helping users identify the best model that balances quality and affordability. This feature is particularly useful for teams looking to optimize their budgets while achieving high-quality outputs.
Consistency Checks
The platform includes tools to verify the consistency of model outputs across repeated runs. This is crucial for applications where reliability is key. By assessing how models perform under the same conditions multiple times, users can ensure that the selected model meets their stability requirements.
Use Cases
Agenta
Streamlined Team Collaboration
Agenta serves as a central hub where product managers, developers, and domain experts can work together seamlessly. This collaboration fosters an environment of innovation, driving the development of more effective LLM applications.
Efficient Prompt Iteration
Using Agenta, teams can rapidly iterate on prompts while tracking changes and comparing different models side-by-side. This feature allows for quick experimentation, which is essential in optimizing LLM performance.
Systematic Performance Evaluation
Agenta enables teams to replace guesswork with evidence-based evaluations. By systematically tracking results and validating every change, teams can ensure that their models are continually improving.
Enhanced Debugging Processes
With Agenta’s observability features, teams can quickly debug their AI systems by tracing requests and identifying failure points. This significantly reduces the time spent on troubleshooting and enhances overall system reliability.
OpenMark AI
Model Selection for Development
Developers can utilize OpenMark AI to make informed choices about which AI model to integrate into their applications. By comparing the performance of multiple models on specific tasks, teams can select the one that aligns best with their project goals and user needs.
Cost-Benefit Analysis
Product teams can conduct thorough cost-benefit analyses to determine which model offers the best value for their investment. By examining real costs alongside performance metrics, teams can make strategic decisions that enhance their budget management and overall ROI.
Quality Assurance in AI Features
Quality assurance teams can leverage OpenMark AI to validate the outputs of AI features before they go live. By running tests and analyzing consistency, they can ensure that the model delivers expected results, reducing the risk of errors in production.
Academic Research and Experimentation
Researchers can use OpenMark AI to benchmark various models for academic purposes. By testing different LLMs on a range of tasks, researchers can contribute valuable insights into model performance and characteristics, aiding the broader AI community in understanding model capabilities.
Overview
About Agenta
Agenta is an innovative open-source LLMOps platform tailored for AI teams that aspire to develop and deploy reliable, production-ready large language model (LLM) applications. In a landscape where large language models can be highly unpredictable, Agenta addresses a critical challenge faced by many teams: the lack of structured processes to manage the complexities of AI development. Often, prompts are dispersed across various communication channels such as emails, Slack, and Google Sheets, leading to fragmented workflows. Agenta brings together developers, product managers, and subject matter experts in a collaborative hub where they can experiment, evaluate, and debug LLM applications with ease. By centralizing prompt management, evaluation, and observability, Agenta ensures that teams can transition from chaotic practices to systematic LLMOps best practices. This facilitates a quicker iteration process while instilling confidence in the reliability and performance of AI applications, allowing teams to innovate without the fear of unpredictable outcomes.
About OpenMark AI
OpenMark AI is a powerful web application designed specifically for task-level benchmarking of large language models (LLMs). It enables users to describe their testing requirements in plain language, run consistent prompts against a variety of models in a single session, and efficiently compare crucial metrics such as cost per request, latency, scored quality, and stability across multiple runs. This capability allows users to observe variance in outputs, moving beyond mere reliance on single, potentially unrepresentative results. Tailored for developers and product teams, OpenMark AI helps in making informed decisions about which model to validate before launching AI-driven features. With hosted benchmarking that operates using credits, there is no need to configure separate API keys for different models, making the testing process streamlined and user-friendly. By focusing on cost efficiency and consistent output quality, OpenMark AI is an essential tool for those who prioritize both performance and budget in their AI implementations.
Frequently Asked Questions
Agenta FAQ
What types of teams can benefit from using Agenta?
Agenta is designed for AI development teams, including developers, product managers, and domain experts, who want to collaborate effectively in building reliable LLM applications.
How does Agenta improve collaboration among team members?
By centralizing prompts, evaluations, and observability in one platform, Agenta fosters collaboration among various roles, allowing teams to work together more efficiently and effectively.
Can Agenta be integrated with existing tools and frameworks?
Yes, Agenta seamlessly integrates with a wide range of tools and frameworks, including LangChain, LlamaIndex, and OpenAI. This flexibility ensures that teams can leverage their existing tech stack while benefiting from Agenta's features.
What makes Agenta different from other LLMOps platforms?
Agenta stands out due to its open-source nature, commitment to collaboration, and its comprehensive approach to prompt management, evaluation, and observability, all in a single platform designed for the entire LLM development lifecycle.
OpenMark AI FAQ
What kind of models can I test with OpenMark AI?
OpenMark AI supports a large catalog of models, including those from OpenAI, Anthropic, Google, and more. This extensive selection allows users to benchmark a wide variety of LLMs to find the best fit for their specific tasks.
Do I need to set up API keys to use OpenMark AI?
No, OpenMark AI simplifies the benchmarking process by using hosted benchmarking that operates on credits. This means you do not need to configure separate API keys for different models, allowing for a smoother testing experience.
How does OpenMark AI ensure the accuracy of its results?
OpenMark AI performs real API calls to the models, providing side-by-side results based on actual outputs rather than cached or marketing numbers. This ensures that users receive accurate and relevant benchmarking data for their comparisons.
Are there any free trials or plans available for OpenMark AI?
Yes, OpenMark AI offers both free and paid plans, allowing users to explore the features and capabilities of the platform. Users can sign up to receive 50 free credits to start their benchmarking journey without any initial investment.
Alternatives
Agenta Alternatives
Agenta is an open-source platform designed for LLMOps, helping teams collaborate effectively in building and managing reliable large language model applications. By centralizing tasks like prompt management, evaluation, and observability, Agenta addresses the complexities of AI development, ensuring teams can work cohesively rather than in silos. Users often seek alternatives to Agenta for various reasons, including pricing constraints, specific feature sets, or compatibility with existing workflows. When considering alternatives, it's essential to look for platforms that offer similar collaboration capabilities, robust evaluation frameworks, and flexibility in experimenting with multiple LLM models, ensuring they meet the unique needs of your team.
OpenMark AI Alternatives
OpenMark AI is a cutting-edge web application designed for task-level benchmarking of large language models (LLMs). It enables users to compare over 100 models based on cost, speed, quality, and stability, making it an essential tool for developers and product teams seeking to validate or choose a model before integrating AI features into their products. By allowing users to run prompts in plain language without the need for multiple API keys, OpenMark AI simplifies the evaluation process. Users often seek alternatives to OpenMark AI for various reasons, including pricing structures, specific feature sets, or unique platform requirements. When searching for an alternative, it's crucial to consider factors such as the range of supported models, the ease of use of the interface, and whether the solution provides transparent performance metrics. Assessing these elements will help ensure that you find a benchmarking tool that aligns with your team's needs and project goals.